How to view the Page Indexing Report in Google Search Console
The Page Indexing report is found in the left-hand menu within Google Search Console. Click on the button labelled Pages.
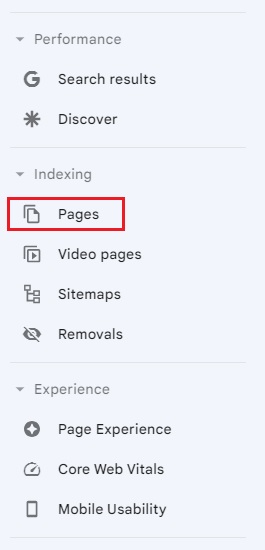
Once selected, you will be presented with a breakdown of your website’s indexability by page.
Elements of the Page Indexing Dashboard
- Primary Crawler – This is the primary Google crawler used for your website. A crawler is an automated program that reviews the text, images, videos, code and links on your website. Since 2020, Google has moved to mobile-first indexing for all websites. If there is a mobile version of your website, Google will default to the Smartphone Crawler for indexing.
- Last Updated – The last time Google ran an update on this particular indexing issue.
- Export – This button allows you to export data about the daily number of indexed pages, not indexed pages, and page impressions, over the previous months. The data also includes index issues, how many pages are affected and whether Google is reviewing your fixes.
- Page Filter – This allows you to filter the results to show the indexing status of pages.
- Not Indexed vs Index – By default, not indexed pages (grey) and indexed pages (green) are both shown in the chart. You can filter to show both, or one at a time.
- Impressions – This toggles page impression numbers on and off. Impression numbers are displayed as a blue line across the bar chart.
- View Data About Indexed Pages – This provides a list of URLs that are currently indexed on your website.
Viewing indexing issues on your website
It’s crucial that the pages on your website are indexed. If a page isn’t indexed, it won’t be displayed in Google search results.
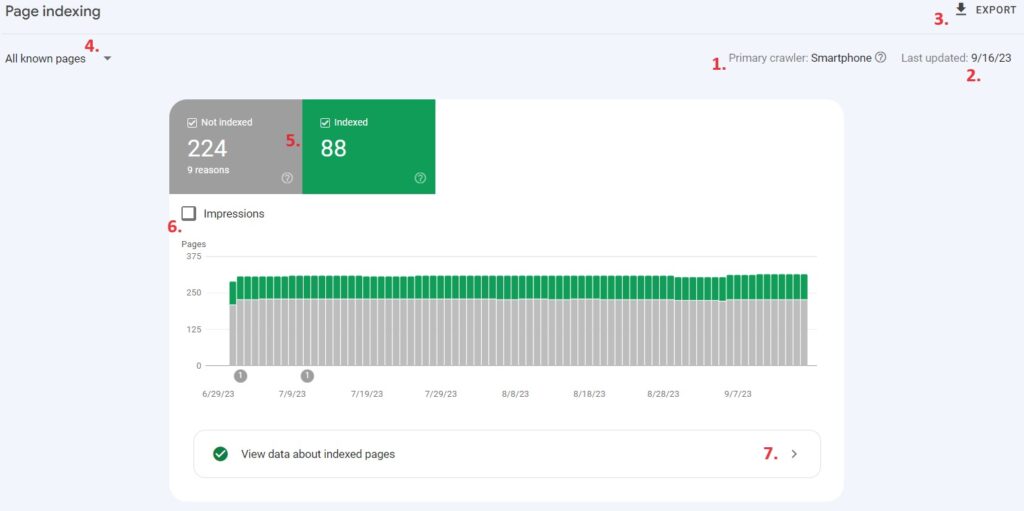
Luckily, the Page Indexing Report can tell you why a page hasn’t been indexed:
If you click on one of the indexing errors, Google will provide a sample of the URLs on your website that are affected by that error:
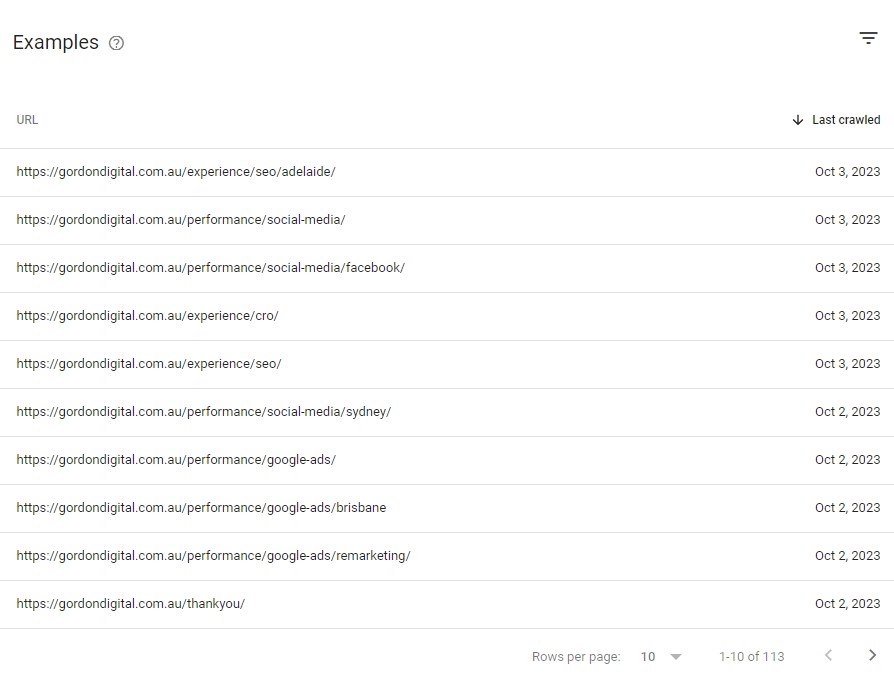
Note the Last crawled column. This indicates when Google last tried to index the page. Sometimes, you’ll find historical issues that may already be resolved.
To remove an error, click the Validate Fix button. Google will start the process of “validating” the URLs listed in the sample. If the URLs can now be indexed (or if the URLs are no longer found), they will be removed from the list and you’ll have up-to-date data!
You can also investigate each of the listed URLs in more detail by clicking the magnifying glass symbol:

Here, you can see how Google discovered the URL, the date of the crawl, whether indexing was allowed, and canonical information:
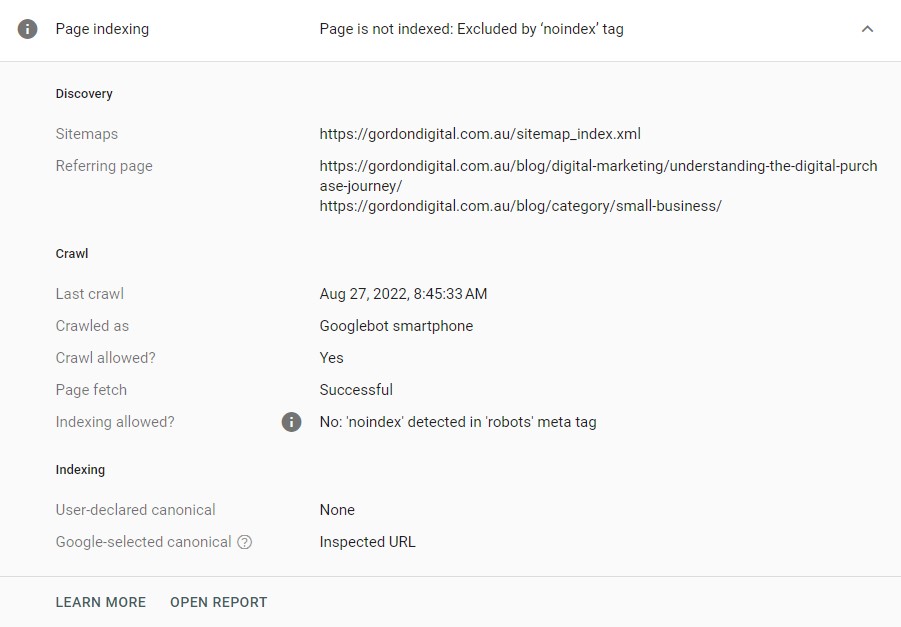
With this, you can determine if the indexing issue is legitimate, or if the page is not appearing in search results as intended.
Common reasons your web pages aren’t being indexed
Below are some of the most common reasons web pages aren’t indexed by Google, and what you can do to resolve the issue. Make sure you check the Last Crawled column next to the URL before you spend time trying to resolve issues.
“Page with redirect”
Google Says: This is a non-canonical URL that redirects to another page. As such, this URL will not be indexed. The URL targeted by the redirect may or may not be indexed, depending on what Google thinks about that target URL.
Google can’t index these URLs as they are automatically redirected to a new page. While there are certain types of temporary URL redirects, this issue usually occurs when there are permanent redirects on your website.
This typically isn’t a problem. If you permanently redirect a web page, you don’t want Google to index the original page anyway.
You should still attempt to resolve the issue by updating internal links to their final destination URL. For instance, if you combine two similar pages, internal links pointing to the page that was removed should be updated, rather than relying on the permanent redirect.
Permanent redirects should be kept to a minimum where possible. This improves user experience, which is good news for your SEO strategy and customers.
Avoid having multiple redirects in a row (e.g. a redirect that points to another page that has been redirected). Multiple redirects and redirect loops can impact Google’s ability to crawl a website efficiently.
“Alternate page with proper canonical tag”
Google Says: This page is marked as an alternate of another page (that is, an AMP page with a desktop canonical, or a mobile version of a desktop canonical, or the desktop version of a mobile canonical). This page correctly points to the canonical page, which is indexed, so there is nothing you need to do. Alternate language pages are not detected by Search Console.
Canonical tags are used to inform search engines that a different URL should be indexed, as this page appears similar (or is identical) to existing content.
If you are getting this warning on a page you want Google to index, double-check the rel=canonical tag in the page’s source code to ensure it’s self-referencing.
“Duplicate, Google chose different canonical than user”
Google Says: This page is marked as canonical for a set of pages, but Google thinks another URL makes a better canonical. Google has indexed the page that it considers canonical, rather than the one you marked as canonical.
This problem is the opposite of the one above. Google is choosing to override a valid canonical reference by the user.
Canonical tags are not a directive. Google may still choose not to index a page. This typically happens when Google feels another page is too similar to the page you are trying to index.
“Not found (404)”
Google Says: This page returned a 404 error when Google attempted to crawl it. Google discovered this URL without any explicit request or sitemap. Google might have discovered the URL as a link from another page, or the page may have been deleted.
Google cannot index a page if it no longer exists.
“Excluded by ‘noindex’ tag”
Google Says: When Google tried to index the page it encountered a ‘noindex’ directive and therefore did not index it. If you don’t want this page indexed then you don’t need to do anything further. If you do want this page to be indexed, you should remove the ‘noindex’ directive.
We don’t always want to index every page on a website. Things such as members-only content can be protected by the noindex directive. This directive tells Google not to index the page.
If you get this error on pages that you do want to index, you will need to review the page’s robot meta tag. If your tag is not set to index as shown below, you will need to investigate how the tag was changed:
meta name=’robots’ content=’index’
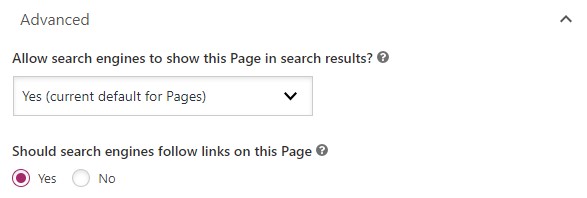
If you’re using WordPress and the Yoast SEO plugin, double check your Yoast Page Settings. Underneath Advanced, both settings need to be set to ‘yes’ to keep the meta robots tag set to index and follow:
“Server error (5XX)”
Google Says: Your server returned a 500-level error when the page was requested.
You will see this indexing error when Googlebot couldn’t access the URL in question. This usually happens if the request timed out, or if your site was too busy to serve the page.
There are many things that can cause a page to time out, including excessive page loading times, hosting problems or aggressive security (such as firewalls unintentionally blocking Googlebot).
“URL blocked by robots.txt”
Google Says: This page was blocked by your site’s robots.txt file.
The website’s robot.txt file includes directives that prevent Google from crawling certain URLs or URLs paths. You can test the crawlability of URLs using Google’s robots.txt tester.
“Soft 404”
Google Says: The page request returns what we think is a soft 404 response. This means that it returns a user-friendly “not found” message but not a 404 HTTP response code. We recommend returning a 404 response code for truly “not found” pages and adding more information on the page to let us know that it is not a soft 404.
This error means Googlebot feels the page is a 404 page, despite the fact that it did not serve a 404 HTTP response code.
This could be a page with no main content, or it may simply be an empty page. It could also be pages that have been automatically generated by your webserver or content management system (CMS).
“Crawled – currently not indexed”
Google Says: The page was crawled by Google but not indexed. It may or may not be indexed in the future; no need to resubmit this URL for crawling.
Pages that are crawled but not indexed by Google are typically low quality, thin on content, provide no value for searches, or have a combination of these traits.
You can fix this error by improving content and reevaluating onpage elements so that the page provides value for searches.
Validating your fixes
Indexing is one of the core principles of SEO. If you want your website to climb through the search rankings, you should regularly check the Page Indexing Report and resolve issues.
Once you fix a problem, you can use the Validate Fix button to let Google know that the problem is resolved. When you click the button, Google will re-check the current list of issues and remove any that are no longer valid.

This can take a few days. Once the process is complete, Google will email you with the result, and you can review the Page Indexing Report to see if any issues still remain.
Get on top of indexing issues with Gordon Digital
SEO is a complex field. There’s lots to learn, and there are plenty of little tricks you can use to help your website rank higher.
But before you try anything fancy, it’s important to get the basics right. Indexing can make or break your website, and it should be a regular part of your SEO strategy.
Indexing isn’t a set-and-forget kind of thing, either. Websites need to be updated, technical issues can break your pages, and Google can change its algorithm anytime. When that happens, you’ll need to check your Page Indexing Report to make sure nothing has gone wrong.
The best way to stay on top of indexing issues is to work with a team of pros! We offer Brisbane SEO services that include regular reviews of indexing reports. That means we can fix any issues you’re having and help your website make it to the top of Google.
Get in touch with us to have a chat. We’d love to design an SEO strategy that helps you kick your business goals!